 付款。
付款。(在家觀看 = 0%,在校觀看 = 100%)
100% 在校觀看日期及時間:
自由選擇,點選以下地區觀看辦公時間及位置

課時: 30 小時
享用時期: 15 星期。進度由您控制,可快可慢。
課堂錄影導師:Larry
在校免費試睇:首 3 小時,請致電以上地點與本中心職員預約。
本課程提供在校免費重睇及導師解答服務。
(在家觀看 = 100%,在校觀看 = 0%)
100% 在家觀看日期及時間:
每天 24 小時全天候不限次數地觀看
課時: 30 小時
享用時期: 15 星期。進度由您控制,可快可慢。
課堂錄影導師:Larry
在校免費試睇:首 3 小時,請致電以上地點與本中心職員預約。
本課程提供導師解答服務。
機器學習是什麼?
機器學習 (Machine Learning) 是一種透過算法和統計模型,讓電腦系統能夠自動從數據當中發掘相關性,從而作出數據預測及輔助人類進行決策的技術。

機器學習是人工智能的一個範疇,使電腦系統能夠在不需要明確的人手編程的情況下,通過大量訓練數據自行學習和改進。
MLflow 是一個開放源始碼 (Open Source) 平台,其目標是管理機器學習的生命周期,包括實驗追蹤、模型管理、部署以及集中儲存。MLflow 亦幫助數據科學家 (Data Scientist) 更有效地開發、訓練和管理機器學習模型。
以下列出使用 Microsoft Azure Machine Learning 和 MLflow 的十大優勢:
- 集成環境:Azure Machine Learning 提供了與 MLflow 的無縫集成 (Seamless Integration),使您管理機器學習實驗和部署過程更加簡單高效。
- 自動化機器學習:Azure 提供自動化機器學習功能,能夠自動選擇最合適的算法和超參數,提升模型準確性。
- 可擴展性:Azure 的雲服務架構可隨意擴展,以處理大量數據和突發的運算需求,滿足不同規模的機器學習任務。
- 實驗追蹤:使用 MLflow 可以輕鬆追蹤和比較不同的模型實驗,記錄每次運行的參數和結果,方便您人手選擇最佳模型。
- 模型管理:MLflow 支持模型版本控制和儲存,確保模型的可重現性和可追溯性,便於在生產環境中的部署和管理。
- 靈活的部署選項:Azure Machine Learning 提供多種部署選項,包括雲端 (Cloud)、邊緣 (Edge) 設備和本地 (On-Premises) 環境,滿足不同的業務需求。
- 安全性:Azure 提供企業級的安全措施,保護數據和模型的安全性,確保合規性和隱私。
- 可視化工具:內建的可視化工具和儀表板幫助用戶更直觀地了解數據和模型的表現,提升分析效率。
- 協作功能:支持多用戶協作,團隊成員可以共享實驗結果和模型資源,促進團隊合作和知識共享。
- 高效的資源管理:Azure 的計算資源可以按需分配和管理,避免資源浪費,降低運營成本。
這些優勢使得使用 Microsoft Azure Machine Learning 和 MLflow 成為許多企業和開發者進行機器學習開發和部署的首選方案。
以下是在不同行業的應用機器學習的真實例子:
- 金融業
風險管理與欺詐檢測:利用 Azure ML 和 MLflow 建立模型來分析交易數據,識別潛在的欺詐行為,提高風險管理效率。
投資分析:使用機器學習算法預測股票市場趨勢,幫助投資決策。
- 醫療健康
疾病診斷:通過 Azure ML 訓練圖像識別模型,協助醫生進行疾病診斷,提升診斷準確性。
個性化治療:分析病患數據,提供個性化的治療方案,提高治療效果。
- 零售業
需求預測:使用 MLflow 追蹤和管理模型來預測商品需求,優化庫存管理。
客戶分析:分析消費者行為數據,進行精準營銷,提升客戶滿意度。
- 製造業
預測性維護:通過 Azure ML 建立設備故障預測模型,減少停機時間和維修成本。
質量控制:運用機器學習來檢測產品缺陷,提高生產質量。
許多世界五百強企業正在使用 Azure Machine Learning 和 MLflow 來提升業務效率和創新能力,例如:
- 沃爾瑪 (Walmart):利用機器學習進行需求預測和庫存管理。
- 雀巢 (Nestle):使用機器學習優化供應鏈管理和產品質素。
- 輝瑞 (Pfizer):應用於藥物研發和個性化醫療方案。
- 豐田 (Toyota):預測性維護和生產自動化,提升生產效率,減少維修停機時間。
- 美國銀行 (Bank of America):應用於欺詐檢測和客戶服務優化,降低欺詐損失,提升客戶體驗。
- 殼牌 (Shell):應用於設備監控和能源管理,為旗下全球44,000個油站實行即時監控及減低火災風險,提高能源利用效率,降低營運成本。
- 福特 (Ford):應用於自動駕駛技術和產品設計優化,推動創新,加速產品開發。
- AT&T:應用於網絡性能優化和客戶預測分析,提升網絡穩定性,降低客戶流失。
- 強生 (Johnson & Johnson):應用於醫療設備診斷和預測分析,提高產品可靠性,改善患者結果。
- 埃克森美孚 (ExxonMobil):應用於油田生產優化和資源管理,提高生產力,降低資源消耗。
這些世界五百強企業透過使用 Azure Machine Learning 和 MLflow,獲得了更高的營運效率和市場競爭力,並推動了創新與可持續發展。
關於 Data Scientist 的行業角色、認證及本課程
成為微軟認證的 Azure Data Scientist Associate,您可以幫助您的企業或機構達到以下目標:
- 提升決策質量:通過準確的數據分析和預測模型,幫助企業做出更明智的決策。
- 提高運營效率:優化流程和資源配置,利用機器學習自動化重複性任務。
- 持續創新:推動創新項目,探索新的商業機會和產品。
- 風險管理:通過分析和預測,幫助企業降低風險,提升安全性。
而透過學習本課程,您將會獲得深入的 Azure 機器學習及 MLflow 知識,提高 A.I. 相關的技術專長,增加就業及晉升競爭力。

Microsoft Certified: Azure Data Scientist Associate
我們的資深講師 Larry Chan 將為您提供各種 Microsoft Azure Machine Learning 及 MLflow 相關產品的建議和操作技巧,令您為企業或機構實施以下的日常職務:
- 數據建模:設計和實施數據模型,使用 Azure Machine Learning 來解決商業問題。
- 機器學習實驗:設計和運行機器學習實驗,選擇合適的算法和方法。
- 數據分析:分析數據並生成有意義的見解,支持商業決策。
- 模型部署和管理:使用 MLflow 管理模型的版本控制和部署,確保模型在生產環境中運行順利。
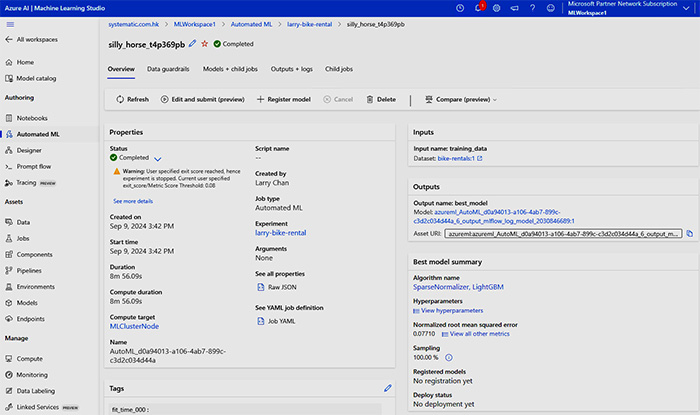
在本課程內操作 Azure Machine Learning 及 MLflow 去訓練數據模型的實例:
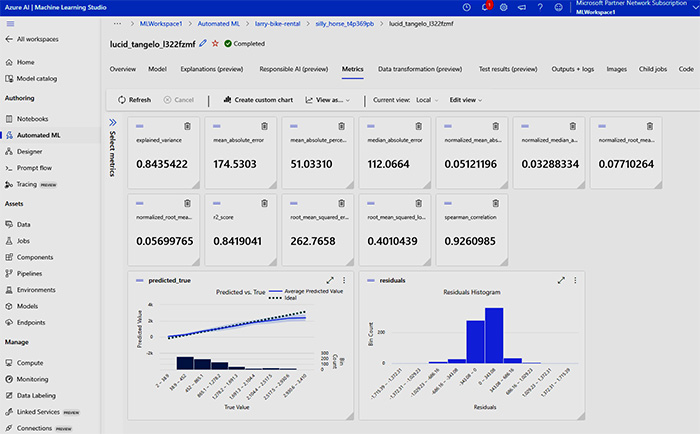
在本課程內對訓練數據模型進行監察及優化的實例:
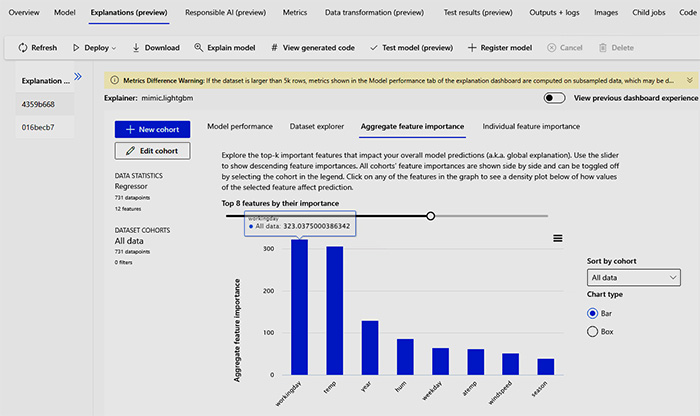
在本課程內對訓練數據模型進行分析實例:
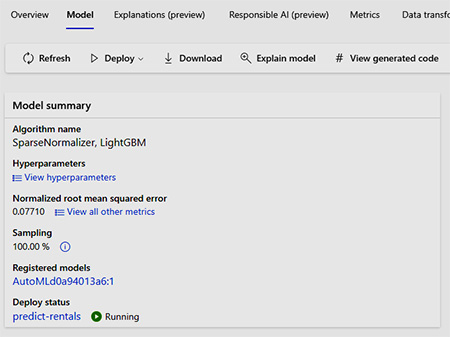
在本課程內對訓練數據模型部署至雲端實例:
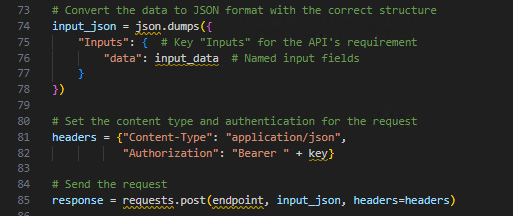
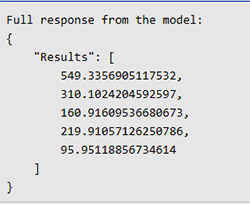
在本課程內以 Python REST API Request,利用自行訓練的數據模型作出預測的實例:
| 課程名稱: |
Microsoft Certified Azure Data Scientist Associate (1科 Azure Machine Learning 及 MLflow) 國際認可證書課程 - 簡稱:Azure Data Scientist Training Course |
| 課程時數: | 30 小時 (共 10 堂,共 1 科) |
| 適合人士: | 有志考取 Microsoft Certified: Azure Data Scientist Associate 證書人士 |
| 授課語言: | 以廣東話為主,輔以英語 |
| 課程筆記: | 本中心導師親自編寫英文為主筆記,而部份英文字附有中文對照。 |
| 1. 模擬考試題目: | 本中心為學員提供模擬考試題目,每條考試題目均附有標準答案。 |
| 2. 時數適中: | 本中心的 Microsoft Certified Azure Data Scientist Associate (1科 Azure Machine Learning 及 MLflow) 國際認可證書課程時數適中,有 30 小時。 令學員能真正了解及掌握課程內容,而又能於短期內考獲以下 1 張國際認可證書:
|
| 3. 導師親自編寫筆記: | 由本中心已擁有五項 MCITP , 十多項 MCTS,MCSA 及 MCSE 資格,並有教授 Microsoft 相關課程 20年以上經驗的資深導師 Larry Chan 親自編寫筆記,絕對適合考試及實際管理之用,令你無須「死鋤」如字典般厚及不適合香港讀書格調的書本。 |
| 4. 一人一機上課: | 本課程以一人一機模式上課。 |
| 5. 免費重讀: | 傳統課堂學員可於課程結束後三個月內免費重看課堂錄影。 |
Microsoft 已公佈考生只要通過以下 1 個 Azure Data Scientist 相關科目的考試,便可獲發 Microsoft Certified Azure Data Scientist Associate 國際認可證書:
| 考試編號 | 科目名稱 |
| DP-100 | Designing and Implementing a Data Science Solution on Azure |
本中心為Microsoft指定的考試試場。報考時請致電本中心,登記欲報考之科目考試編號、考試日期及時間
(最快可即日報考)。臨考試前要出示身份證及繳付每科HK$943之考試費。 考試不合格便可重新報考,不限次數。欲知道作答時間、題目總數、合格分數等詳細考試資料,可瀏覽本中心網頁 "各科考試分數資料"。 |
|
課程名稱:Microsoft Certified Azure Data Scientist Associate (1科 Azure Machine Learning 及 MLflow) 國際認可證書課程 - 簡稱:Azure Data Scientist Training Course |
DP-100 Designing and Implementing a Data Science Solution on Azure
1. Design a Data Ingestion Strategy
1.1 Identify your data source and format
1.2 Identify the data source
1.3 Identify the data format
1.3.1 Tabular or structured data
1.3.2 Semi-structured data
1.3.3 Unstructured data
1.4 Identify the desired data format
1.5 Choose how to serve data to machine learning workflows
1.5.1 Separate compute from storage
1.5.2 Store data for model training workloads
1.6 Design a data ingestion solution
1.6.1 Azure Synapse Analytics
1.6.2 Azure Databricks
1.6.3 Azure Machine Learning
1.6.4 Design a data ingestion solution
1.7 Scenario-based Exercise for Designing a Data Ingestion Technology
1.7.1 The Scenario: Give advice on how to ingest and serve the data
1.7.2 What type of data do we currently have?
1.7.3 Which storage solution would you recommend to store the data?
1.7.4 Which tool would you recommend we use to move the data?
1.7.5 Which tool should we use to anonymize the patient data?
1.7.6 Which architecture represents the proposed data ingestion solution?
2. Design a machine learning model training solution
2.1 Identify machine learning tasks
2.2 Capabilities of Azure Machine Learning
2.3 Regression with Azure Machine Learning
2.3.1 Create an Azure Machine Learning workspace
2.3.2 Create compute resources
2.3.3 Explore data
2.3.4 Train a machine learning model
2.3.5 Review the best model
2.3.6 Deploy a model as a service
2.3.7 Test the deployed service
2.3.8 Clean-up
2.4 Choose a service to train a machine learning model
2.5 Decide between compute options
2.5.1 CPU or GPU
2.5.2 General purpose or memory optimized
2.5.3 Spark
2.5.4 Monitor the compute utilization
2.6 Scenario-based Exercise for Designing a Model Training Strategy
2.6.1 How should we train the model to predict diabetes?
2.6.2 Which tool should we use to train the diabetes model?
2.6.3 Which compute would you recommend to train the model?
2.6.4 Which virtual machine size should we use for model development?
2.6.5 How should we train another model to predict skin disorders?
3. Design a model deployment solution
3.1 Understand how model will be consumed
3.1.1 Deploy a model to an endpoint
3.1.2 Get real-time predictions
3.1.3 Get batch predictions
3.2 Decide on real-time or batch deployment
3.2.1 Identify the necessary frequency of scoring
3.2.2 Decide on the number of predictions
3.2.3 Consider the cost of compute
3.2.4 Decide on real-time or batch deployment
3.3 Scenario-based Exercise for Designing a Model Deployment Solution
4. Design a machine learning operations solution
4.1 Explore an MLOps architecture
4.1.1 Set up environments for development and production
4.1.2 Organize Azure Machine Learning environments
4.1.3 Design an MLOps architecture
4.2 Design for monitoring
4.2.1 Monitor the model
4.2.2 Monitor the data
4.2.3 Monitor the infrastructure
4.3 Design for retraining
4.3.1 Prepare your code
4.3.2 Automate your code
4.4 Scenario-based Exercise for Machine Learning Operations
5. Azure ML Workspace Resources and Assets
5.1 Create an Azure Machine Learning workspace
5.1.1 Understand the Azure Machine Learning service
5.1.2 Create the workspace
5.1.3 Give access to the Azure Machine Learning workspace
5.1.4 Organize your workspaces
5.2 Identify Azure Machine Learning resources
5.2.1 Create and manage the workspace
5.2.2 Create and manage compute resources
5.2.3 Create and manage datastores
5.3 Identify Azure Machine Learning assets
5.3.1 Create and manage models
5.3.2 Create and manage environments
5.3.3 Create and manage data
5.3.4 Create and manage components
5.4 Train models in the workspace
5.4.1 Explore algorithms and hyperparameter values with Automated Machine Learning
5.4.2 Run a notebook
5.4.3 Run a script as a job
5.5 Explore the Azure Machine Learning workspace
5.5.1 Provision an Azure Machine Learning workspace
5.5.2 Explore the Azure Machine Learning studio
5.5.3 Author a training pipeline
5.5.4 Create a compute target
5.5.5 Run your training pipeline
5.5.6 Use jobs to view your history
6. Developer tools for workspace interaction
6.1 New Features in v2
6.2 Explore the Python SDK
6.2.1 Install the Python SDK
6.2.2 Connect to the workspace
6.3 Explore the CLI
6.3.1 Install the Azure CLI
6.3.2 Install the Azure Machine Learning extension
6.3.3 Work with the Azure CLI
6.4 Explore developer tools for workspace interaction
6.4.1 Before you start
6.4.2 Provision the infrastructure with the Azure CLI
6.4.3 Create a compute instance with the Azure CLI
6.4.4 Create a compute cluster with the Azure CLI
6.4.5 Configure your workstation with the Azure Machine Learning studio
6.4.6 Use the Python SDK to train a model
6.4.7 Review your job history in the Azure Machine Learning studio
7. Make Data Available in Azure Machine Learning
7.1 Understand URIs
7.2 Datastore
7.2.1 Understand types of datastores
7.2.2 Use the built-in datastores
7.2.3 Create a datastore
7.2.4 Create a datastore for an Azure Blob Storage container
7.3 Data Asset
7.3.1 Understand data assets
7.3.2 When to use data assets
7.3.3 Create a URI file data asset
7.3.4 Create a URI folder data asset
7.3.5 Create a MLTable data asset
7.4 An Exercise of Making data available in Azure Machine Learning
7.4.1 Provision an Azure Machine Learning workspace
7.4.2 Create the workspace and compute resources
7.4.3 Explore the default datastores
7.4.4 Copy the access key
7.4.5 Clone the lab materials
7.4.6 Create a datastore and data assets
7.4.7 Optional: Explore the data assets
8. Compute Targets in Azure Machine Learning
8.1 Choosing the appropriate compute target
8.1.1 Understand the available types of compute
8.1.2 When to use which type of compute?
8.1.3 Choose a compute target for experimentation
8.1.4 Choose a compute target for production
8.1.5 Choose a compute target for deployment
8.2 Create and use a compute instance
8.2.1 Create a compute instance with the Python SDK
8.2.2 Assign a compute instance to a user
8.2.3 Minimize compute time
8.2.4 Use a compute instance
8.3 Create and use a compute cluster
8.3.1 Create a compute cluster with the Python SDK
8.3.2 Using a compute cluster
8.4 Exercise of Working with compute resources in Azure Machine Learning
8.4.1 Provision an Azure Machine Learning workspace
8.4.2 Create the compute setup script
8.4.3 Create the compute instance
8.4.4 Configure the compute instance
8.4.5 Create a compute cluster
9. Working with environments in Azure Machine Learning
9.1 Understanding Environments
9.1.1 What is an environment in Azure Machine Learning?
9.2 Explore and use curated environments
9.2.1 Use a curated environment
9.2.2 Test and troubleshoot a curated environment
9.3 Create and use custom environments
9.3.1 Create a custom environment from a Docker image
9.3.2 Create a custom environment with a conda specification file
9.3.3 Use an environment
9.4 Work with environments in Azure Machine Learning
9.4.1 Provision an Azure Machine Learning workspace
9.4.2 Create the workspace and compute resources
9.4.3 Clone the lab materials
9.4.4 Work with environments
10. Finding the best Classification model with Automated Machine Learning
10.1 Preprocess data and configure featurization
10.1.1 Understand scaling and normalization
10.1.2 Configure optional featurization
10.2 Run an Automated Machine Learning experiment
10.2.1 Restrict algorithm selection
10.2.2 Configure an AutoML experiment
10.2.3 Specify the primary metric
10.2.4 Set the limits
10.2.5 Set the training properties
10.2.6 Submit an AutoML experiment
10.3 Evaluate and compare models
10.3.1 Explore preprocessing steps
10.3.2 Retrieve the best run and its model
10.4 Exercise of Finding the best classification model with Automated Machine Learning
10.4.1 Provision an Azure Machine Learning workspace
10.4.2 Create the workspace and compute resources
10.4.3 Clone the lab materials
10.4.4 Train a classification model with automated machine learning
11. Tracking model training in Jupyter notebooks with MLflow
11.1 Configure MLflow for model tracking in notebooks
11.1.1 Configure MLflow in notebooks
11.1.2 Use MLflow on a local device
11.2 Train and track models in notebooks
11.2.1 Create an MLflow experiment
11.2.2 Log results with MLflow
11.2.3 Enable autologging
11.2.4 Use custom logging
11.3 Exercise of Tracking Model Training in Notebooks by using MLflow
11.3.1 Provision an Azure Machine Learning workspace
11.3.2 Create the workspace and compute resources
11.3.3 Clone the lab materials
11.3.4 Track model training with MLflow
12. Training Script as Command Job
12.1 Convert a notebook to a script
12.1.1 Remove all nonessential code
12.1.2 Refactor your code into functions
12.1.3 Test your script
12.2 Run a script as a command job
12.2.1 Configure and submit a command job
12.3 Use parameters in a command job
12.3.1 Working with script arguments
12.3.2 Passing arguments to a script
12.4 Exercise on Running a training script as command job
12.4.1 Provision an Azure Machine Learning workspace
12.4.2 Create the workspace and compute resources
12.4.3 Clone the lab materials
12.4.4 Convert a notebook to a script
12.4.5 Test a script with the terminal
12.4.6 Run a script as a command job
13. Track model training with MLflow in jobs
13.1 View metrics and evaluate models
13.1.1 View the metrics in the Azure Machine Learning studio
13.1.2 Retrieve metrics with MLflow in a notebook
13.1.3 Search all the experiments
13.1.4 Retrieve runs
13.2 Exercise Using MLflow to track training jobs
13.2.1 Provision an Azure Machine Learning workspace
13.2.2 Create the workspace and compute resources
13.2.3 Clone the lab materials
13.2.4 Submit MLflow jobs from a notebook
14. Hyperparameter tuning with Azure Machine Learning
14.1 Concepts on Hyperparameter
14.1.1 Hyperparameters
14.1.2 Parameters
14.1.3 Tuning hyperparameters
14.2 Define a search space
14.2.1 Discrete hyperparameters
14.2.2 Continuous hyperparameters
14.2.3 Defining a search space
14.3 Three common Hyperparameters in Regression
14.3.1 Learning rate
14.3.2 Batch size
14.3.3 Epochs
14.4 Configure a sampling method
14.4.1 Grid sampling
14.4.2 Random sampling
14.4.3 Sobol
14.4.4 Bayesian sampling
14.5 Early Termination
14.5.1 When to use an early termination policy
14.5.2 Configure an early termination policy
14.5.3 Bandit policy
14.5.4 Median stopping policy
14.5.5 Truncation selection policy
14.6 Using a Sweep Job for Hyperparameter tuning
14.6.1 Configure and run a sweep job
14.6.2 Monitor and review sweep jobs
14.7 Exercise of Perform hyperparameter tuning with a sweep job
14.7.1 Provision an Azure Machine Learning workspace
14.7.2 Create the workspace and compute resources
14.7.3 Clone the lab materials
14.7.4 Tune hyperparameters with a sweep job
15. Run pipelines in Azure Machine Learning
15.1 Create components
15.2 Create a pipeline
15.3 Run a pipeline job
15.4 Exercise of Running pipelines in Azure Machine Learning
15.4.1 Provision an Azure Machine Learning workspace
15.4.2 Create the workspace and compute resources
15.4.3 Clone the lab materials
15.4.4 Run scripts as a pipeline job
16. Register an MLflow model in Azure Machine Learning
16.1 Log models with MLflow
16.1.1 Why use MLflow?
16.1.2 Use autologging to log a model
16.1.3 Manually log a model
16.1.4 Customize the signature
16.2 The MLflow model format
16.2.1 Explore the MLmodel file format
16.2.2 MLmodel file
16.2.3 Flavor
16.2.4 Configure the signature
16.3 Register an MLflow model
16.4 Exercise of Logging and Registering models with MLflow
16.4.1 Provision an Azure Machine Learning workspace
16.4.2 Create the workspace and compute resources
16.4.3 Clone the lab materials
16.4.4 Submit MLflow jobs from a notebook
17. Responsible AI in Azure Machine Learning
17.1 Understanding Responsible AI
17.1.1 Fairness and inclusiveness
17.1.2 Reliability and safety
17.1.3 Transparency
17.1.4 Privacy and security
17.1.5 Accountability
17.2 Create the Responsible AI dashboard
17.2.1 Create a Responsible AI dashboard
17.2.2 Explore the Responsible AI components
17.2.3 Build and run the pipeline to create the Responsible AI dashboard
17.2.4 Using the Python SDK to build and run the pipeline
17.2.5 Exploring the Responsible AI dashboard
17.3 Evaluate the Responsible AI dashboard
17.3.1 Explore error analysis
17.3.2 Explore explanations
17.3.3 Explore counterfactuals
17.3.4 Explore causal analysis
17.4 Exercise Creating and Exploring the Responsible AI dashboard
17.4.1 Provision an Azure Machine Learning workspace
17.4.2 Create the workspace and compute resources
17.4.3 Clone the lab materials
17.4.4 Create a pipeline to evaluate models and submit from a notebook
18. Deploying a model to Managed Online Endpoint
18.1 Explore managed online endpoints
18.1.1 Real-time predictions
18.1.2 Managed online endpoint
18.1.3 Deploy your model
18.1.4 Blue/green deployment
18.1.5 Create an endpoint
18.2 Deploy your MLflow model to a managed online endpoint
18.3 Deploy a model to a managed online endpoint
18.3.1 Create the scoring script
18.3.2 Create an environment
18.3.3 Create the deployment
18.4 Testing Managed Online Endpoints
18.4.1 Use the Azure Machine Learning Python SDK
18.5 Exercise Deploying an MLflow model to an online endpoint
18.5.1 Provision an Azure Machine Learning workspace
18.5.2 Create the workspace and compute resources
18.5.3 Clone the lab materials
18.5.4 Deploy a model to an online endpoint
19. Deploying model to Batch Endpoint
19.1 Understanding Batch endpoints
19.1.1 Batch predictions
19.1.2 Create a batch endpoint
19.1.3 Deploy a model to a batch endpoint
19.1.4 Using compute clusters for batch deployments
19.2 Deploy your MLflow model to a batch endpoint
19.2.1 Register an MLflow model
19.2.2 Deploy an MLflow model to an endpoint
19.3 Deploy a custom model to a batch endpoint
19.3.1 Create the scoring script
19.3.2 Create an environment
19.3.3 Configure and create the deployment
19.4 Invoke and troubleshoot batch endpoints
19.4.1 Trigger the batch scoring job
19.4.2 Troubleshoot a batch scoring job
19.5 Exercise Deploying Model to a Batch endpoint
19.5.1 Provision an Azure Machine Learning workspace
19.5.2 Create the workspace and compute resources
19.5.3 Clone the lab materials
19.5.4 Deploy a model to Batch Endpoint
20. Azure AI Search solution
20.1 Manage Capacity
20.1.1 Service tiers and capacity management
20.1.2 Replicas and partitions
20.2 Search Components
20.2.1 Data source
20.2.2 Skillset
20.2.3 Indexer
20.2.4 Index
20.3 The indexing process
20.4 Search an index
20.4.1 Full text search
20.5 Filtering and Sorting
20.5.1 Filtering results
20.5.2 Filtering with facets
20.5.3 Sorting results
20.6 Enhance the index
20.6.1 Search-as-you-type
20.6.2 Custom scoring and result boosting
20.6.3 Synonyms
20.7 Creating an Azure AI Search Solution
20.7.1 Create Azure resources
20.7.2 Create an Azure AI Search resource
20.7.3 Create an Azure AI Services resource
20.7.4 Create a storage account
20.7.5 Prepare to develop an app in Visual Studio Code
20.7.6 Upload Documents to Azure Storage
20.7.7 Index the documents
20.7.8 Search the index
20.7.9 Explore and modify definitions of search components
20.7.10 Get the endpoint and key for your Azure AI Search resource
20.7.11 Review and modify the skillset
20.7.12 Review and modify the index
20.7.13 Review and modify the indexer
20.7.14 Use the REST API to update the search solution
20.7.15 Query the modified index
20.7.16 Create a search client application
20.7.17 Get the endpoint and keys for your search resource
20.7.18 Prepare to use the Azure AI Search SDK
20.7.19 Explore code to search an index
20.7.20 Explore code to render search results
20.7.21 Run the web app
21. Vector search and retrieval in Azure AI Search
21.1 Concepts about Vector Search
21.2 Prepare your search
21.2.1 Check your index has vector fields
21.2.2 Convert a query input into a vector
21.3 Understand embedding
21.3.1 Embedding models
21.3.2 Embedding space
21.4 Using the REST API to run vector search queries
21.4.1 Set up your project
21.4.2 Create an Index
21.4.3 Upload Documents
21.4.4 Run Queries
22. Introduction to Azure OpenAI Service
22.1 Access Azure OpenAI Service
22.1.1 Create an Azure OpenAI Service resource in the Azure portal
22.1.2 Create an Azure OpenAI Service resource in Azure CLI
22.2 Use Azure AI Studio
22.2.1 Types of generative AI models
22.3 Deploy generative AI models
22.3.1 Deploy using Azure AI Studio
22.3.2 Deploy using Azure CLI
22.3.3 Deploy using the REST API
22.4 Use prompts to get completions from models
22.4.1 Prompt types
22.4.2 Completion quality
22.4.3 Making calls
22.5 Test models in Azure AI Studio's playground
22.5.1 Completions playground
22.5.2 Completions Playground parameters
22.5.3 Chat playground
23. Introduction to Prompt Engineering
23.1 Understand prompt engineering
23.1.1 Considerations for API endpoints
23.1.2 Adjusting model parameters
23.2 Write more effective prompts
23.2.1 Provide clear instructions
23.2.2 Format of instructions
23.2.3 Use section markers
23.2.4 Primary, supporting, and grounding content
23.2.5 Cues
23.3 Provide context to improve accuracy
23.3.1 Request output composition
23.3.2 System message
23.3.3 Conversation history
23.3.4 Few shot learning
23.3.5 Break down a complex task
23.3.6 Chain of thought
24. Retrieval Augmented Generation (RAG) with Azure OpenAI Service
24.1 Concepts of Retrieval Augmented Generation (RAG) with Azure OpenAI Service
24.1.1 Fine-tuning vs. RAG
24.2 Add your own data source
24.2.1 Connect your data
24.3 Chat with your model using your own data
24.3.1 Token considerations and recommended settings
24.3.2 Using the API
24.4 Lab Exercise – Implementing Retrieval Augmented Generation with Azure OpenAI Service
24.4.1 Provision Azure resources
24.4.2 Upload your data
24.4.3 Deploy AI models
24.4.4 Create an index
24.4.5 Prepare to develop an app in Visual Studio Code
24.4.6 Configure your application
24.4.7 Add code to use the Azure OpenAI service
24.4.8 Run your application
25. Transformer Architecture and Large Language Models
25.1.1 Understand artificial intelligence
25.1.2 Understand natural language processing
25.2 Understand statistical techniques used for natural language processing (NLP)
25.2.1 The beginnings of natural language processing (NLP)
25.2.2 Understanding tokenization
25.2.3 Statistical techniques for NLP
25.2.4 Understanding Naive Bayes
25.2.5 Understanding TF-IDF
25.3 Understanding Deep Learning techniques used for Natural Language Processing (NLP)
25.3.1 Word embeddings
25.3.2 Adding memory to NLP models
25.3.3 Using RNNs to include the context of a word
25.3.4 Improving RNNs with Long Short-Term Memory
25.4 Understanding Transformer Architecture used for natural language processing (NLP)
25.4.1 Understand multi-head attention
25.4.2 Using the scaled dot-product to compute the attention function
25.4.3 Explore the Transformer architecture
25.5 Explore foundation models in the model catalog
25.5.1 Explore the model catalog
25.5.2 Explore foundation models
25.6 Exercise Exploring Foundation models in the Model Catalog
25.6.1 Provision an Azure Machine Learning workspace
25.6.2 Explore the model catalog
25.6.3 Explore question answering models
25.6.4 Explore fill mask models
25.6.5 Explore translation models
25.6.6 Deploy the model to a real-time endpoint
25.6.7 Test the deployed translation model
26. Fine-tune a foundation model with Azure Machine Learning
26.1 Understand when to Fine-tune a Foundation Model
26.1.1 Explore foundation models in the model catalog
26.1.2 Fine-tuning foundation models for specific tasks
26.2 Procedures for Fine-tuning Foundation Models
26.2.1 Prepare your data and compute
26.2.2 Choose a foundation model
26.2.3 Configure a fine-tuning job
26.3 Evaluate, deploy, and test a fine-tuned foundation model
26.3.1 Evaluate your fine-tuned model
26.3.2 Deploy your fine-tuned model
26.3.3 Register your model using the Azure Machine Learning studio
26.3.4 Deploy your model using the Azure Machine Learning studio
26.3.5 Test the model in the Azure Machine Learning studio
26.4 Exercise Fine-tuning a foundation model in the Azure Machine Learning studio
26.4.1 Provision an Azure Machine Learning workspace
26.4.2 Create the workspace and upload the dataset
26.4.3 Explore the data
26.4.4 Create a compute cluster
26.4.5 Fine-tune the model
26.4.6 Test the model
26.4.7 Register the model
26.4.8 Deploy the model
26.4.9 Test the endpoint
27. Prompt Flow
27.1 Understand the development lifecycle of a large language model (LLM) app
27.1.1 Initialization
27.1.2 Experimentation
27.1.3 Evaluation and refinement
27.1.4 Production
27.1.5 Explore the complete development lifecycle
27.2 Core components and explore flow types
27.2.1 Understand a flow
27.2.2 Tools available in prompt flow
27.2.3 Types of flows
27.3 Connections and Runtimes
27.3.1 Connections
27.3.2 Runtimes
27.4 Variants and Monitoring options
27.4.1 Variants
27.4.2 Deploy your flow to an endpoint
27.4.3 Monitor evaluation metrics
27.4.4 Metrics
27.5 prompt flow in the Azure Machine Learning Studio
27.5.1 Create the Azure OpenAI service to deploy a GPT model
27.5.2 Provision an Azure OpenAI resource
27.5.3 Save the endpoint and key
27.5.4 Deploy a model
27.5.5 Provision the necessary resources to create a flow
27.5.6 Provision an Azure Machine Learning resource
27.5.7 Create a compute instance
27.5.8 Create a connection
27.5.9 Create and run a flow in Azure Machine Learning
27.5.10 Configure the inputs
27.5.11 Configure the LLM node
27.5.12 Configure the Python node
27.5.13 Configure the output
27.5.14 Run the flow